Overview
Sometimes searches result in multiple copies of the same reference; these are called duplicates.
The process of removing duplicates is called de-duplication. De-duplication ensures that busy reviewers (that’s you!) don’t waste time reviewing the same study more than once. In Covidence, studies are identified as duplicates one of two ways: by Covidence during import (system detected duplicates), or by you during screening (manually marked duplicates).
Note that de-duplication in Covidence is distinct from merging, the process of linking multiple unique references which report on the same study (read more about this here).
Transparent reporting of de-duplication is part of best systematic review practice. You’ll find information about duplicates in your review in a few different places:
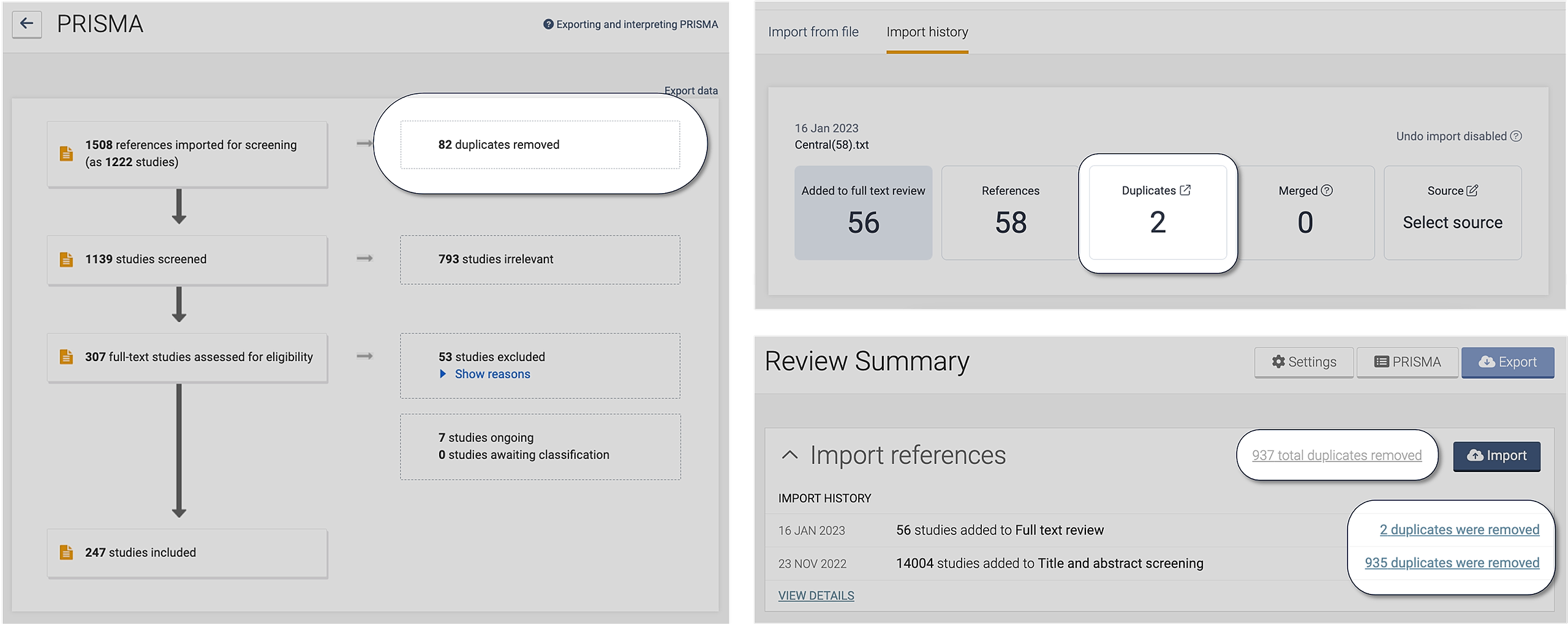
Your review’s PRISMA diagram reports the total number of duplicates identified in Covidence.
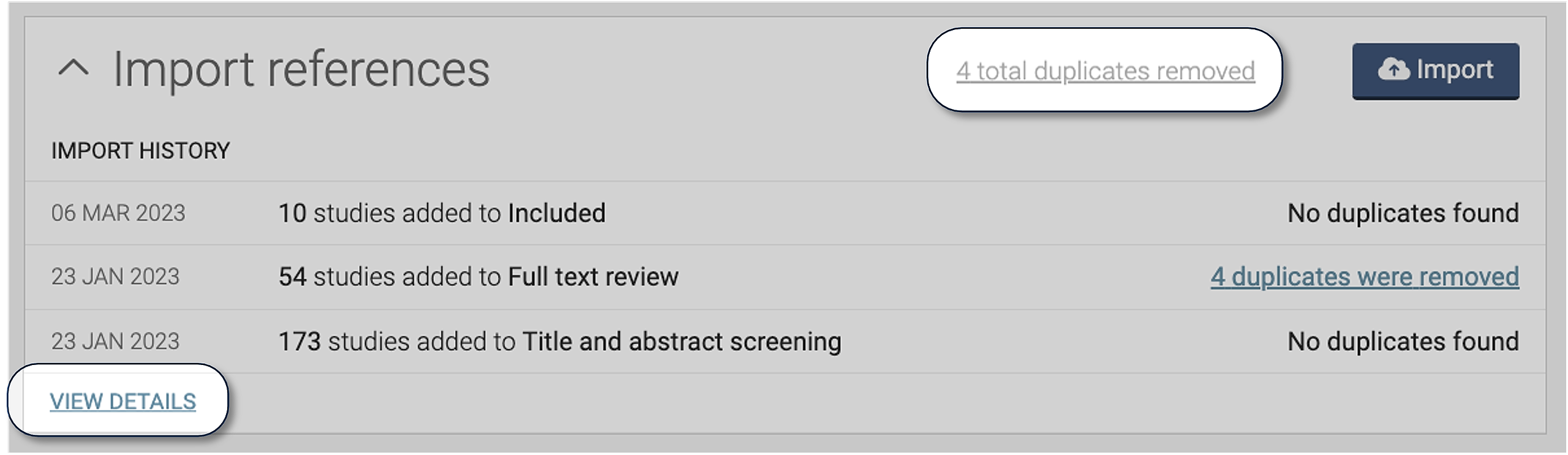
Your Import history page reports the number of duplicates identified within each imported file.
Your Review Summary page shows the five most recent imports and the number of duplicates identified in each one.
Viewing duplicates
To view all the duplicates identified in your review, click on “[number] total duplicates removed” on your Review Summary page, or go to Import History by clicking on “View details”
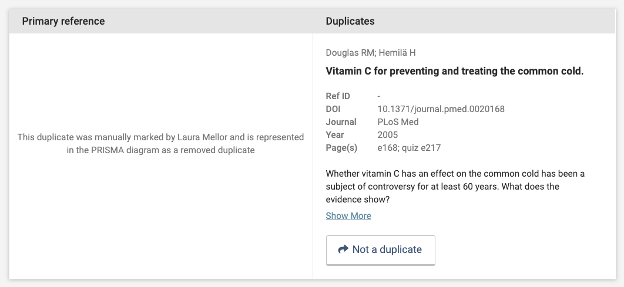
System detected duplicates and manually marked duplicates are listed on separate tabs. The version of a study which is used in your review is labelled as the primary reference. If you think something should not have been marked as a duplicate, click the button that says “Not a duplicate” and it will be returned to your review.
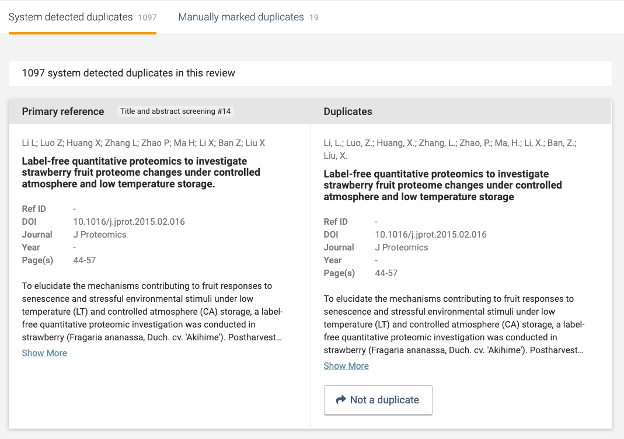
System detected duplicates
When a file is imported to your review, Covidence will automatically check for duplicates within the imported file, as well as against all studies previously imported to that review. The version of the study imported first will be used in your review; all subsequent versions will be sent to the duplicates list.
To identify duplicates, Covidence uses title, year, volume, and authors. You can read more details about this here.
When viewing system detected duplicates, the primary reference is displayed on the left, along with its current stage and Covidence ID number. The duplicate(s) associated with each primary reference are shown on the right.
Covidence expert tip: You can go directly to a study in your review by entering the Covidence ID number (including the hashtag #) in the search bar at the top of the page.
Covidence expert tip: if you want to see only duplicates associated with a particular import, go to the Import history page and then click “Duplicates” on the import of interest!
Manually marked duplicates
Sometimes you’ll spot duplicates during the screening process that were missed by the automated deduplication during import. When this happens, click “Duplicate” below the study in your list:
When viewing manually marked duplicates, rather than a primary reference, you will see which reviewer marked the study as a duplicate.